SPONSORED LINKS
This section provides several tips and techniques you can use to speed up your game applications.
Usually only one buffer is used to hold the display list that is constructed by the CPU and executed by the RCP. However, if you use two display list buffers instead of one, the RCP can execute the drawing process for one frame at the same time as the CPU is constructing the next frame's display list. This technique is called "double buffering." Use this technique to speed up your game's graphics if the graphics are complex and you have plenty of memory.
A display list is a graphics command list that holds the commands necessary to render one frame of graphics. The CPU constructs the display list and then passes it to the RCP to execute it. Double buffering is illustrated here:
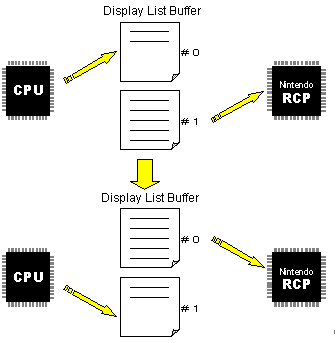
The longer it takes the CPU to construct each display list, the more speed you can add by using the double-buffering technique. But remember that although double-buffering makes it appear as though the display list construction time is zero, it really isn't. The CPU still has to construct each display list and that means the CPU is not available for other processes that might need it. Therefore, you should devise an efficient algorithm to minimize the processing time needed to construct the display list. This can ultimately lead to faster overall game processing.
Note too that double buffering requires twice as much memory to make the two buffers, so if you are short on memory, this technique may not work for you.
Usually, you use two frame buffers (double buffering) as explained in Section 2.2.4, "Use of Frame Buffers". As the RCP is drawing the next frame into one buffer, the video DAC is displaying the previously drawn frame. However, switching between the two frame buffers occurs only at the vertical synchronization point. Therefore, if the RCP hasn't finished drawing a new frame when the next vertical synchronization occurs, you won't be able to use the buffers together for the next frame. In cases like this where it takes longer to draw each frame, you can make the RCP more efficient by using triple frame buffering. One buffer for "displaying," one for "drawing completed and waiting for switch" and one for "drawing" as illustrated here:
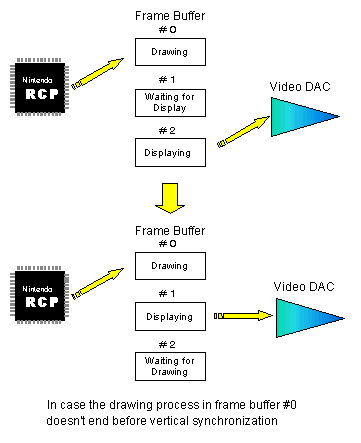
The speed-up effect of this method can be huge when the drawing time of a frame is frequently out of sync with the vertical synchronization timing because the waiting time without triple buffering is long. On the other hand, if the drawing time of a frame is usually in sync with the vertical synchronization, this method has little value because each drawn frame has little waiting time.
You need to weigh the advantages against the disadvantages. Triple buffering uses a lot of memory because each of the three frame buffers are quite large even in low resolution. Also, there is another disadvantage in that the TV display is always two frames behind instead of just one.
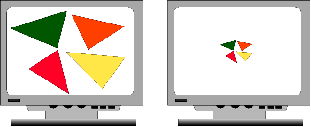
LOD means the level of detail. By providing different levels of detail, you can significantly improve performance. For example, objects that are viewed as fast moving or far away need much less detail than do stationary objects that are close.
When you display a lot of objects on the screen, the RCP processing time increases. The RCP processing time is determined by the time it takes to do vertex coordinate transformations, lighting, and so on done by the RSP microcode and the polygon texturization process of the RDP. When you increase the number of objects to be displayed, the processing time for the vertex coordinate transformation or lighting is sometimes going to be a problem.
When displaying 3D objects that are close, you need to provide a lot of precise detail. On the other hand, when an object is small and far away, you can give very little detail. Therefore you can prepare in advance several versions of a model each with a varying level of detail. Then switch the display model based on the distance of the model from the viewer. This very effectively reduces processing time.
The disadvantages of this technique are that it takes a long time to prepare several LOD versions of each model in order to make the switching appear natural. Also that you need to use memory to store all those models. However, because models that have little detail use very little room, the impact on memory is not too bad. The following illustration uses three levels of detail (LODs):
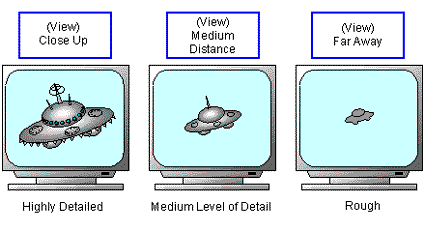
When a model reaches a certain distance from the viewer, you can really improve performance without affecting quality by not showing the model in 3D. Just make it one piece of a picture pasted as pre-rendered image data. This makes it possible to produce good resolution at a fast clip.
Note that this method is most effective when the processing capability of the RSP microcode is saturated, but it has no effect when the RDP performance is saturated.
If the RCP simply displayed all objects on file, it would waste a lot of time processing coordinate transformations for vertices and models that lie outside the current view. To speed up processing, don't process data that is not displayed on the screen.
Volume culling simply means removing those commands from the display list that apply to vertices or models that lie outside the current view. See the gSPCullDisplayList function for details. This concept is illustrated here:
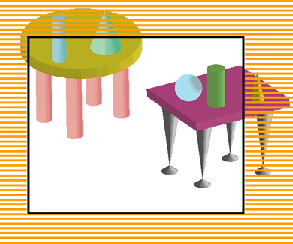
Volume culling is very effective when there are many models or vertices and the processing capability of RSP microcode is saturated, but it has no effect when the RDP performance is saturated.
Anti-aliasing is one of the strongest features of N64. It smoothes out the jagged steps on lines. However, anti-aliasing costs time. It reduces the pixel fill-rate performance of the RDP because the anti-aliasing process needs to update the coverage value of each pixel, read the frame buffer, and write the update. Therefore, memory access of the frame buffer increases by a factor of two. When the RDP fill-rate performance is saturated, you should turn off anti-aliasing. You need to consider the trade off and determine which is most important -- the image quality or the drawing speed.
When you use the Z-buffer, draw the closest object first and then move into the background to get the best speed. If you draw the farthest object first, you have to repeatedly write the entire Z-buffer. Drawing the closest object first is faster because for subsequent object, you need only write that part of the Z-buffer that is not "covered up" by the foreground object. This is a very effective technique when the RDP fill-rate performance is saturated.

There are several ways to optimize GBI commands:


Commands to the RSP microcode are provided by the display list. The processing rate of the microcode varies depending on the way the display list is constructed. The key point is to do a good job of reusing the vertex cache, fetching the vertex data as needed. It is particularly important to optimize the display list when game application creates model data dynamically.
Audio processing time must never be ignored. The audio process needs both CPU and RSP processing time. To decrease the audio processing time, pay attention to these following things:
Nintendo® Confidential
Copyright © 1999
Nintendo of America Inc. All Rights Reserved
Nintendo and N64 are registered trademarks of Nintendo
Last Updated March, 1999